Week 2 | Finding the Right Dataset

This week, we will dive into the first step of the project, finding the right dataset. We will discuss the problem, potential solutions, and the dataset we will use for the project.
Published on September 18, 2023 by Bronte Sihan Li
climate change machine learning AI
3 min READ
This week, we will dive into the first step of the project: finding the right dataset. We will discuss the problem, potential solutions, and the dataset we will use for the project.
For the first phase of the project, we focus on short-term predictions of wildfires. Concretely, this means that we will be predicting the spread of a wildfire, which is a critical task and a difficult problem where there can be many different approaches. However, solving this issue will contribute significantly to land management and fire disaster response efforts, providing useful insights for both emergency teams and individuals that may be in the vicinity of high risk areas.
The Dataset We Will Use
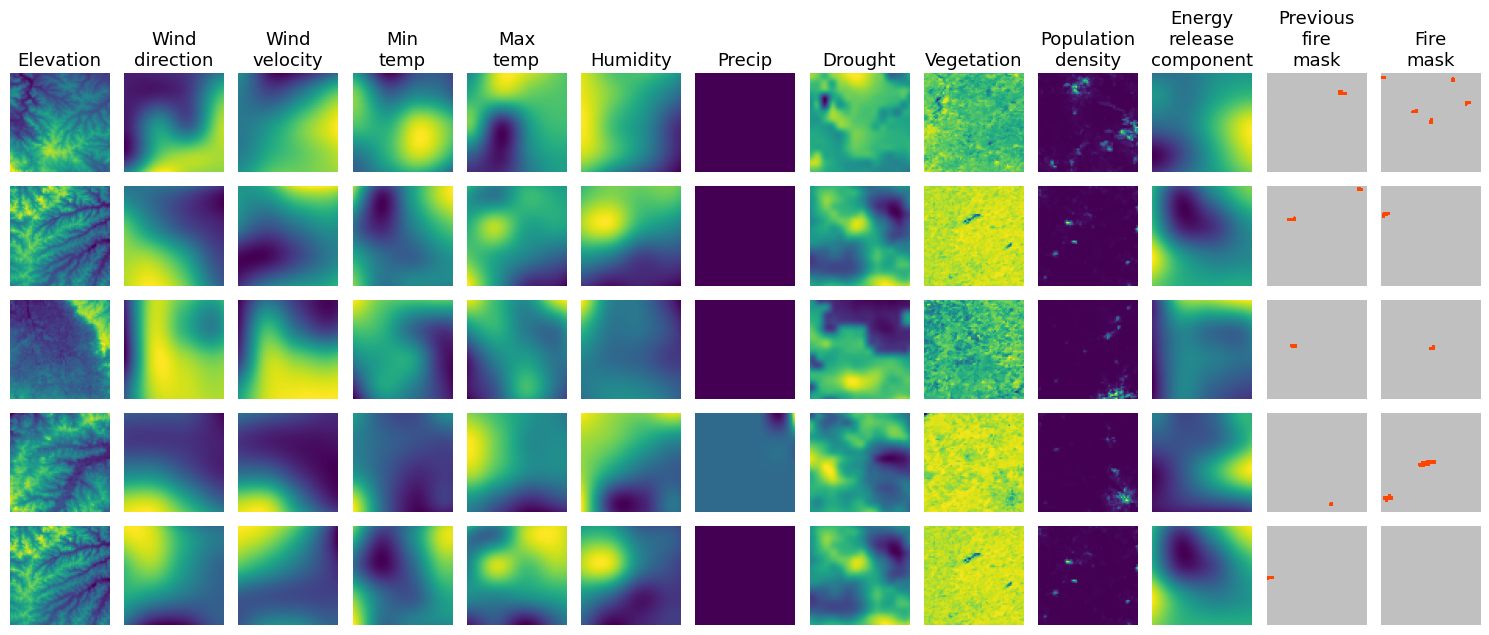
The next day wildfire dataset is a comprehensive compilation of wildfire data from the United States based on Google earth data from 2012 to 2020. It contains 2D information about 12 relevant variables including vegetation, elevation, weather, fire map at t day and fire mask at t+1 day. This dataset has the potential as a benchmark dataset for fire propagation prediction, while there have been few studies on this particular topic. The dataset is publicly available here.
Looking closer at the dataset this week, we were able to identify the specific shapes of the input and output:
The input is a 3D tensor of shape (12, 64, 64), where the first dimension represents the 12 variables relevant to fire spread, the second and third dimensions represent the 64x64 grid of the area of interest. The output is a 2D tensor of shape (64, 64), where each pixel represents the presence of fire at that location.
The visualization below is an example of the input and output for a given day, more details are available from the paper that introduced the dataset here.
Augmenting the Dataset
Due to the drastic increase in number and frequency of wildfires in the last few years, we decided to augment the next day wildfire dataset be expanding its time and location range. We will be using the same 12 variables as the original dataset, but we will be using data from 2012 to 2023, and we will be expanding the area of interest to the entire North America. This will allow us to train a model that can generalize to a more recent time period and a larger area, which will be more useful for real-world applications in the context of this project.
The problem
It is easy to see that the the prediction of the t+1 day fire mask can be framed as a segmentation problem, where the task is classification of each output pixel as either 0 or 1, where 0 means no fire and 1 means fire. However, the input is not a simple image, but a 3D tensor of shape (12, 64, 64). This means that we will need to find a way to transform the input into a 2D image, which we can then use to train a segmentation model.
Potential Solutions
There are a number of potential solutions to this problem, and the original paper for this dataset explores a few of them, including employing both CNN based methods and LSTM based methods as well as using classical machine learning like random forests. While having results from these methods is useful, more sophisticated DNN architectures have not been used on this dataset, and we will start with a simple U-Net to get a baseline for our project.