Week 3 | Unet and Baseline Results

Now that we have our dataset ready, it is time to obtain some baseline results with the goal of 1/ evaluate the difficulty of the problem and 2/ determine if the problem is framed correctly. With that in mind, we will be using the Unet architecture as the starting architecture for this segmentation task.
Published on September 25, 2023 by Bronte Sihan Li
Wildfire Unet Deep Learning machine learning AI
3 min READ
Now that we have our dataset ready, it is time to obtain some baseline results with the goal of 1/ evaluate the difficulty of the problem and 2/ determine if the problem is framed correctly. With that in mind, we will be using the Unet architecture as the starting architecture for this segmentation task.
Framing of the Problem
Before we get into the solution, let’s take a step back and look at the problem we are trying to solve in the context of deep learning. As we saw last week, we are given a 3D tensor of shape (12, 64, 64) as input, and we are trying to predict a 2D tensor of shape (64, 64) as output, which is our next day fire mask. We can think of this as a segmentation problem, where the task is classification of each output pixel as either 0 or 1, where 0 means no fire and 1 means fire. So how do we know how good the prediction is? Two common metrics for segmentation tasks are the Dice coefficient and the Jaccard index.
Given two sets X and Y, Dice coefficient is defined as:
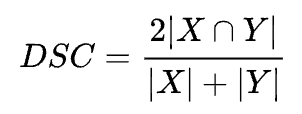
Whereas similarly, the Jaccard index is defined as:
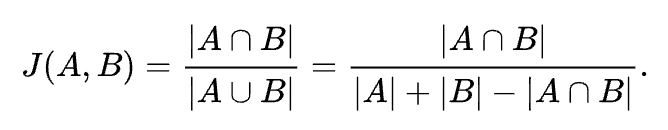
In the context of our fire spread prediction, we can think of the ground truth fire mask as a set of pixels A and the predicted fire mask as a set of pixels B. Then, the Dice coefficient and Jaccard index can be used to evaluate the accuracy of the prediction. The higher the value, the better the prediction.
Unet
Unet is a simple yet powerful architecture originally developed for biomedical imaging segmentation tasks. It is composed of an encoder and a decoder, where the encoder is a series of convolutional layers that downsample the input, and the decoder is a series of convolutional layers that upsample the input. The encoder and decoder are connected by skip connections, which allow the decoder to use information from the encoder to improve the segmentation results. The architecture is shown below:
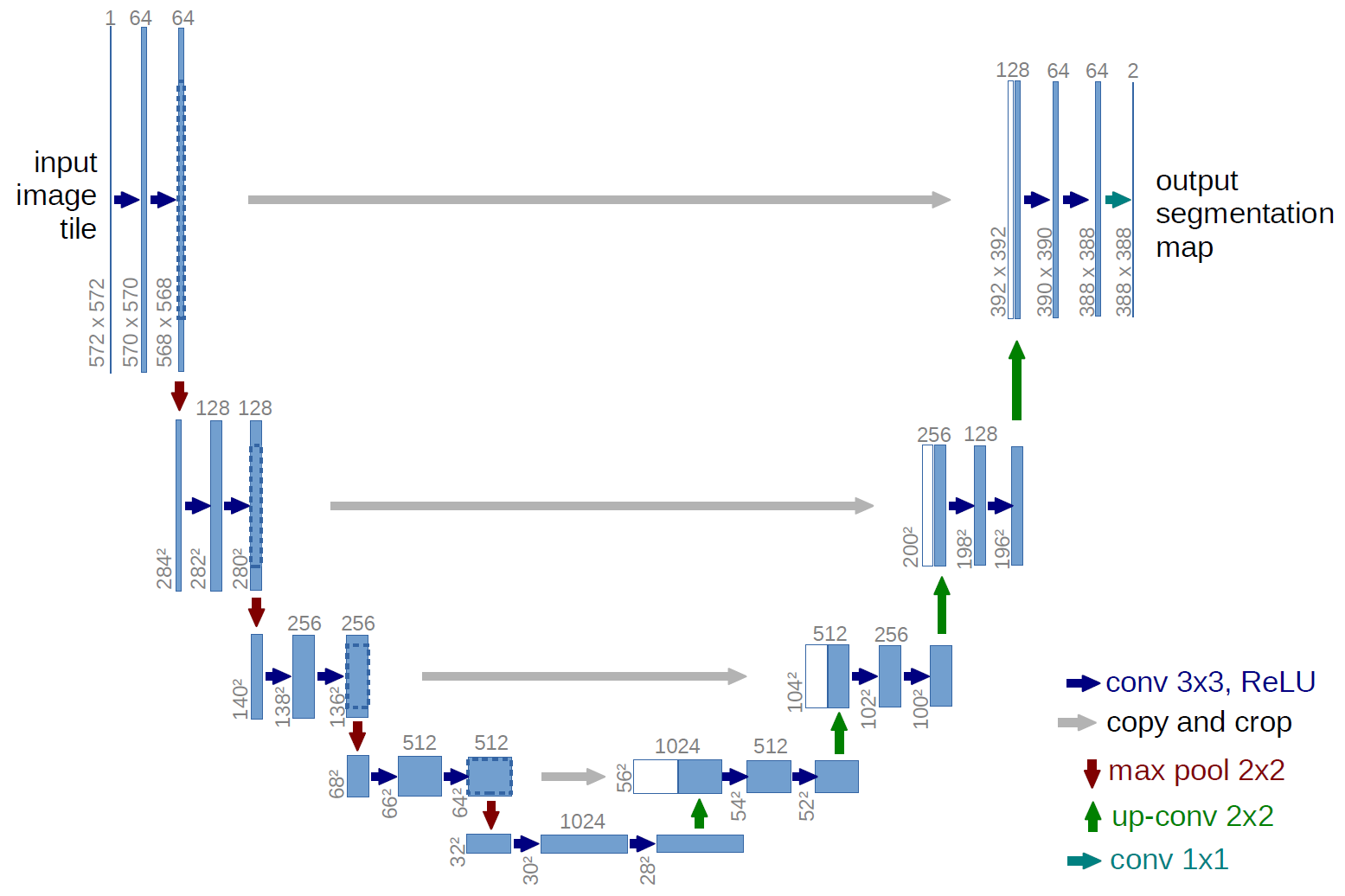
Using this network allows us to get some initial results relatively fast to get a handle on the problem of predicting wildfire spread, and if the results are promising, we can then explore more sophisticated architectures.
Baseline Results
Due to the large size of the dataset and limited GPU resources, we downsampled the dataset from 64x64 to 32x32 and only used the 3 most important dimensions discovered in the original dataset paper: previous day fire mask, vegetation, and elevation. For the loss function, we used binary cross entropy with a positive weight of 100 to account for the imbalance between fire and no fire pixels, and for the optimizer, we used the default Unet scheduler with a learning rate of 1e-5.
The model was trained on an A800-80G GPU for 10 epochs, and we obtained the following results:
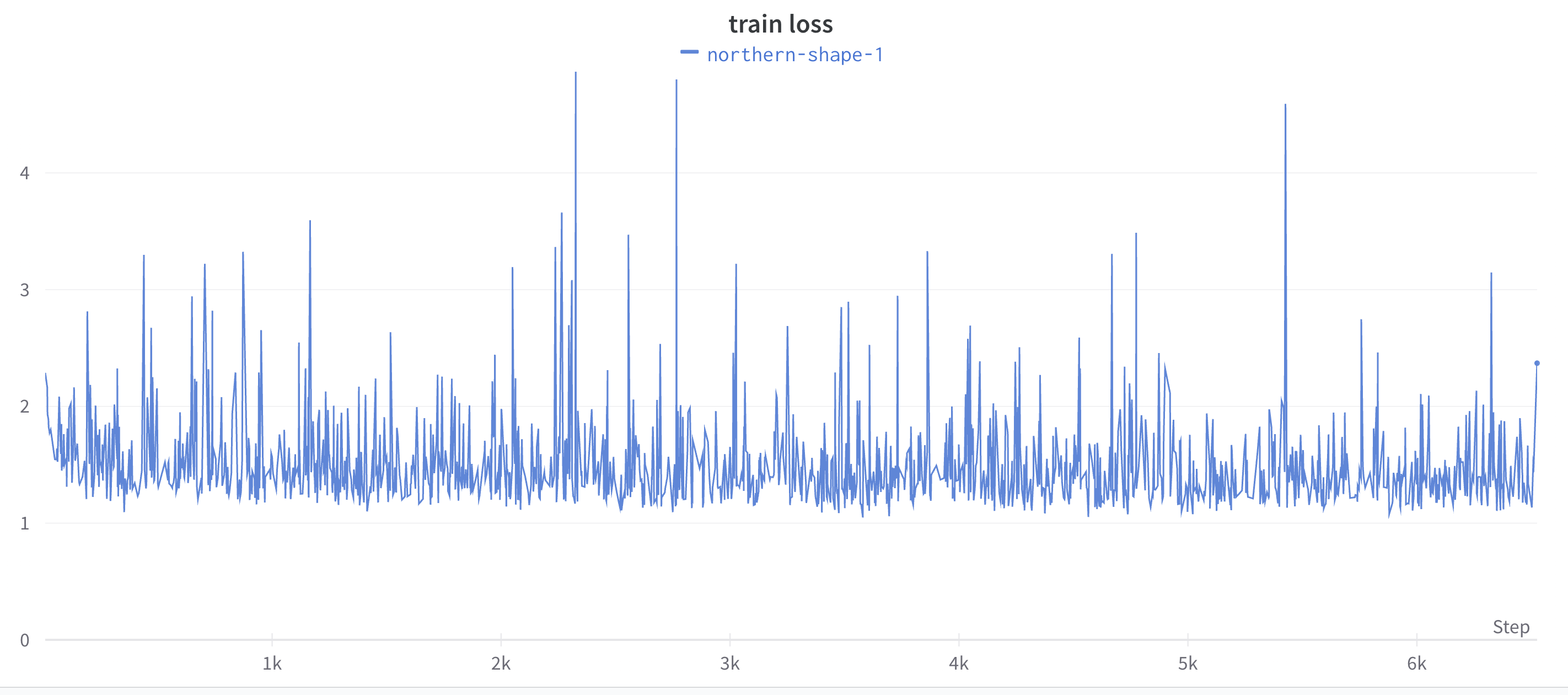
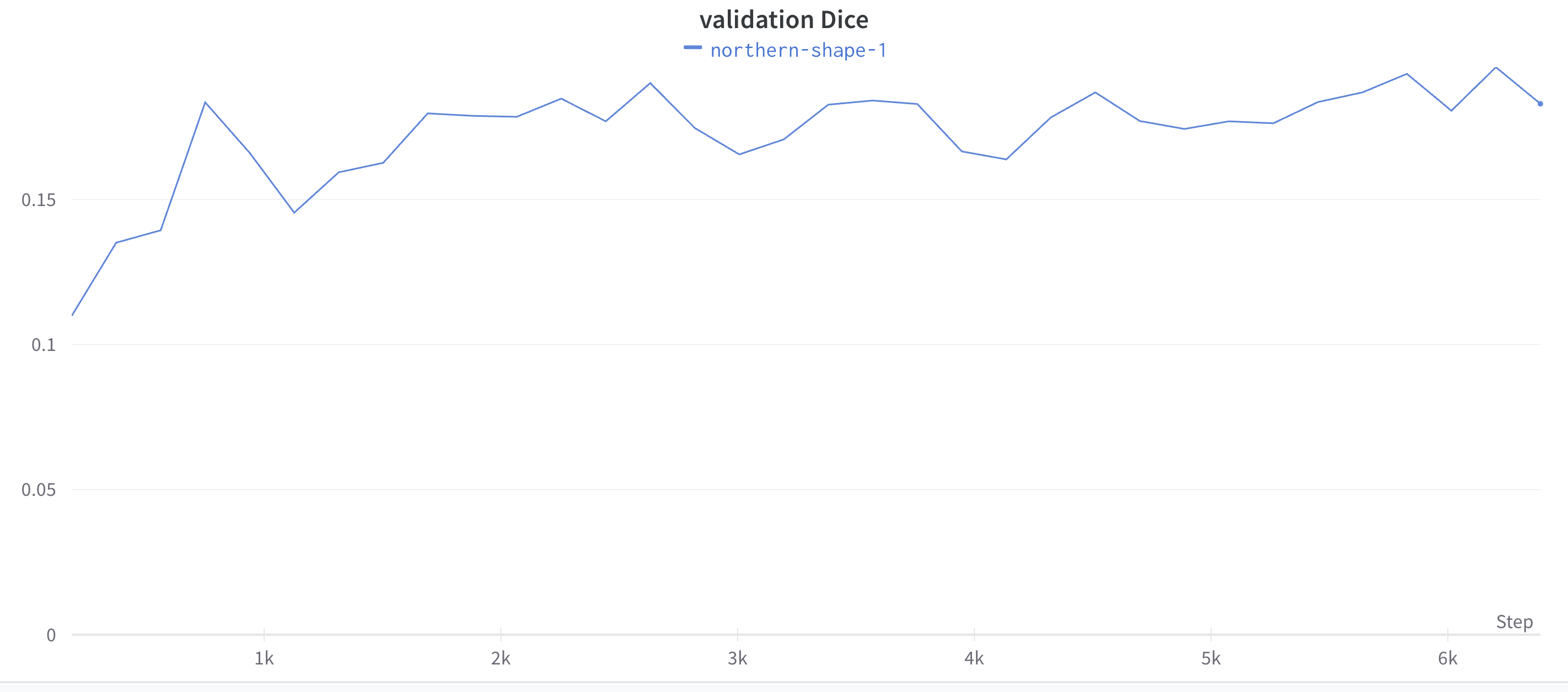
As shown here in the results, we can see that unfortunately the dice score is plateauing at around 0.18, which is not very good. There are a few possible explanations, including the fact that the model is too simple, or the problem is not framed correctly. We will explore these possibilities in the next few weeks.
Next Steps
Next week, we will be exploring the possibility of:
- Preprocessing in different ways the input and target labels to improve the results, for example, by using a different representation of the target labels including using the change in fire rather than fire/no fire. Another idea is to only predict the surrounding the current fire perimeter rather than the entire image, mentioned in the FireCast paper.
- Applying a different loss function that may better reflect the nature of the problem by reviewing and trying out implementations here.