Week 4 | Metrics and Loss Functions

This week, we will dig further into the losses and metrics used by the original next day wild fire paper and train our model using the same losses and metrics on the dataset.
Published on October 02, 2023 by Bronte Sihan Li
Wildfire Deep Learning machine learning AI
3 min READ
With the results from last week, it was clear that we were not approaching the problem correctly. For example, through examining the fire mask prediction results from the trained UNet model, we discovered that by using a loss function that was a combination of binary cross entropy and dice loss, the model was not able to predict the fire masks correctly - in fact, the model was not predicting any positive fire pixels at all. This week, we will dig further into the losses and metrics used by the original next day wild fire paper and train our model using the same losses and metrics on the dataset.
Challenges of the Problem
Looking at the problem of predicting next day wildfire again, it is clear that this is not a typical segmentation problem. The main challenge of this problem is that the fire pixels are very sparse in the image. In fact, the fire pixels only make up about 1% of the image. This means that the model will be trained on a dataset that is very imbalanced. This is a problem because the model will be trained to predict the majority class (non-fire pixels) and will not be able to predict the minority class (fire pixels) well.
Weighted Binary Cross Entropy
Cross entropy is a loss function that is used to measure the performance of a classification model whose output is a probability value between 0 and 1. The loss function is commonly used in machine learning and deep learning models, as the following:
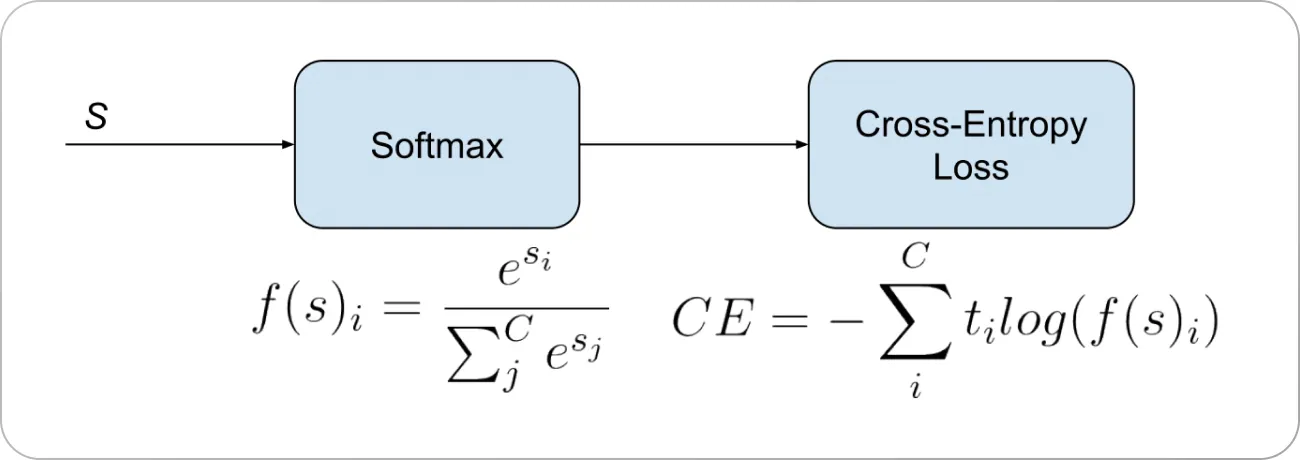
After applying an activation function of either sigmoid or softmax, for each class in the output, the cross entropy loss is calculated. The loss is then summed up for all classes and averaged over all samples. The loss function is then minimized by the model during training.
For our problem of predicting next day fire, we can think of using binary cross entropy to classify at each location on the map the probability of a fire. However, because we have a serious imbalance between the number of positive and negative samples, we need to weight the loss function to account for this imbalance. We can do this by assigning a weight to each class. The weight for the positive class is the inverse of the proportion of positive samples in the dataset, and the weight for the negative class is the inverse of the proportion of negative samples in the dataset. This way, the loss function will be weighted more towards the positive class, and the model will be trained to predict the positive class better. This means that for the next round of experiments, we will be using a weighted binary cross entropy as our only loss function to train our model.
AUC, Precision and Recall
In addition to the weighted binary cross entropy loss function, we will also be using the AUC, precision and recall metrics to evaluate our model. The AUC metric is the area under the ROC curve, which is a plot of the true positive rate (TPR) against the false positive rate (FPR). The TPR is the proportion of positive samples that are correctly identified as positive, and the FPR is the proportion of negative samples that are incorrectly identified as positive.
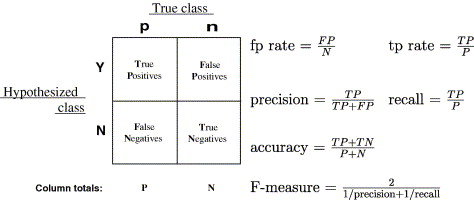

For more information on the ROC curve, see here and here.
Photo by Michael Dziedzic on Unsplash