Week 6 | Exploring Different Ways to Improve

We continue to look for ways to improve the performance of our model, by adding additional features adn using Unet with attention. We also discuss another loss function that we will try.
Published on October 22, 2023 by Bronte Sihan Li
Wildfire Deep Learning machine learning AI UNet Segmentation
3 min READ
This week, we continue to look for ways to improve the performance of our model, by adding additional features and using Unet with attention. We also discuss another loss function that we will try.
Adding Additional Features
While we were able to achieve higher PR-AUC than the current benchmark using only 3 out of the 12 input features, we continued to explore the potential of the UNet architecture by adding more features. Therefore, we retrained the UNet model and added humidity(sph) and precipitation as input features. As a result, we were able to improve the PR-AUC score to 0.31 after training for only 5 epochs, which is already a significant improvement from the previous PR-AUC score of 0.293. Given this promising result, we will continue to explore the potential of the UNet architecture by adding more features, though it is worth mentioning that computational resources are limited and we will need to be careful about the number of features added, given the large dataset size and the significant increase in the number of parameters in the model.
UNet with Attention
Attention UNet[1] was first introduced to be able to focus on the pancreas in CT scans. The authors of the paper proposed a new architecture that combines the UNet architecture with attention gates. The attention gate is a mechanism that allows the model to focus on the most relevant features in the input. The attention gate is a 2D tensor of the same size as the input, and it is multiplied with the input to produce the output. The attention coefficients identify salient image regions and prune input features to preserve only activations relevant to the specific tasks. As a result, the attention gate is able to filter the input and focus on the most relevant features, which is useful for our problem of predicting next day wildfire, as the fire pixels are very sparse in the image and we want to apply more weight to the previous day fire mask.
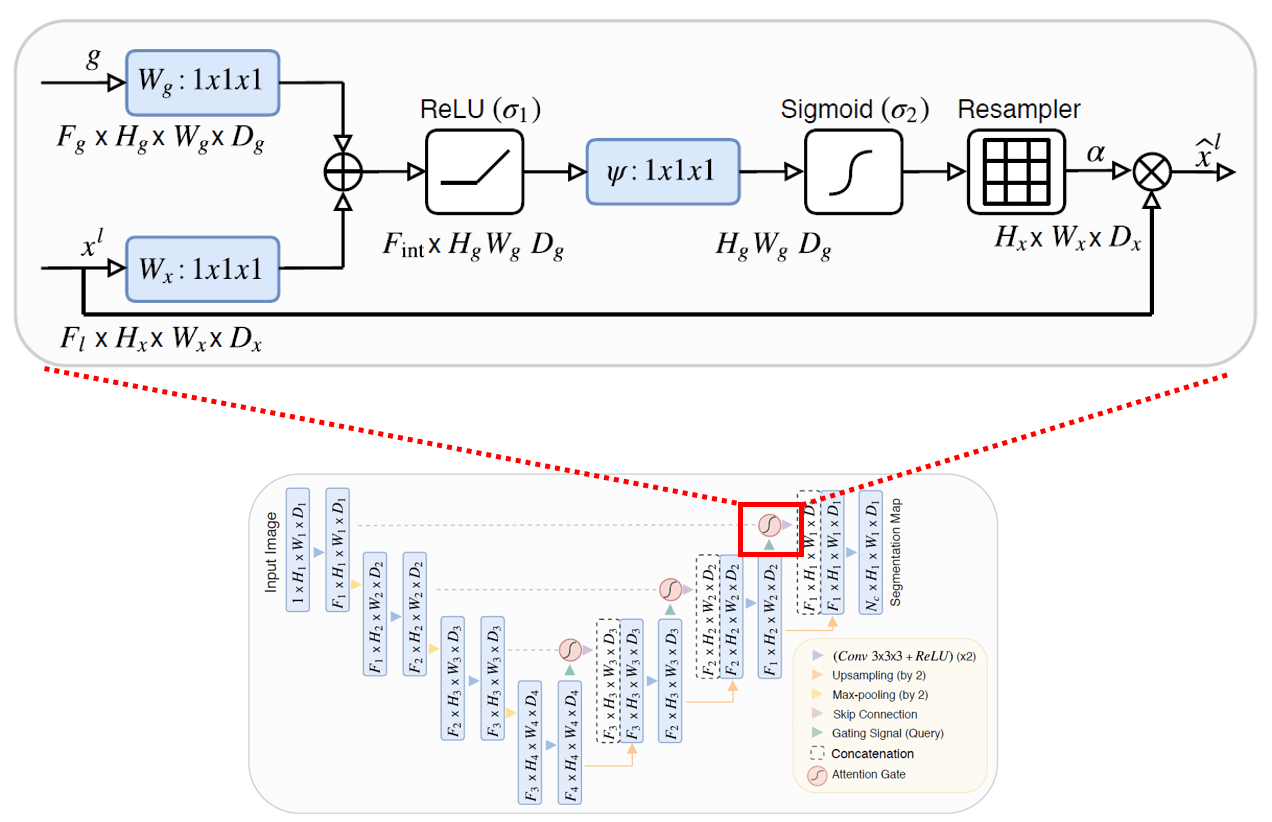
Furthermore, we would like to continue exploring other more advanced networks including recurrent attention UNet and attention UNet with residual connections. We will also explore the potential of using other attention mechanisms such as self-attention and non-local attention, as well as vision transformers.
Focal Loss and Tversky Focal Loss
Focal loss[2] is a loss function that is used to address the problem of class imbalance. The loss function is a modification of the cross entropy loss function, where the loss is weighted by a factor that is inversely proportional to the class frequency. The loss function is defined as follows:
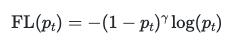
This loss function adds an additional focusing factor, gamma that allows for more weight to be applied to the hard examples. This is useful for our problem and worth a try, as the fire pixels are very sparse in the image, and we want to apply more weight to the fire pixels. Additionally, in [2] the authors proposed a new loss function called Tversky focal loss, which is a modification of the focal loss function, which uses the Tversky index, a generalization of the Dice score to allow for flexibility in balancing false positives and false negatives:
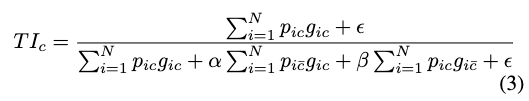
Then the Tversky focal loss is defined as:
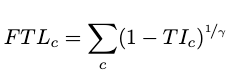
Due to the presence of many small ROI in our training samples, we will experiment with using this loss function similar to the study in [3] which also predicts the spread of wildfires using a different dataset.
- Oktay, Ozan et al. “Attention U-Net: Learning Where to Look for the Pancreas.” ArXiv abs/1804.03999 (2018): n. pag.
- Abraham, Nabila and Naimul Mefraz Khan. “A Novel Focal Tversky Loss Function With Improved Attention U-Net for Lesion Segmentation.” 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019) (2018): 683-687.
- Zou Y, Sadeghi M, Liu Y, Puchko A, Le S, Chen Y, Andela N, Gentine P. Attention-Based Wildland Fire Spread Modeling Using Fire-Tracking Satellite Observations. Fire. 2023; 6(8):289. https://doi.org/10.3390/fire6080289
Photo by JOHN TOWNER on Unsplash